Identifier les limites de l'IA générative
Rappel du module précédent
Utiliser l'IA Agentique
Ses 3 caractéristiques principales pour définir l'IA Agentique :
- Autonomie : capable d’agir et de prendre des décisions sans supervision humaine continue.
- Proactivité : capable d’initier des actions pour atteindre ses objectifs, au lieu de seulement réagir à des commandes.
- Capacité d’adaptation : capable d’ajuster son comportement en fonction du contexte, des retours et de l’évolution de l’environnement.
Limites et freins à l’IA Générative
L’IA générative ouvre de nouvelles perspectives, mais elle reste
imparfaite. Ses productions peuvent contenir des erreurs, des biais ou manquer
de cohérence, ce qui limite sa fiabilité.
À cela s’ajoutent des freins
techniques, éthiques et juridiques qui freinent son adoption à grande échelle.
Parmi les freins et limites les plus courants, on retrouve notamment :
- Hallucinations
- Biais algorithmique
- Réglementations
- Exploitation des données
Hallucinations
Présentation de la limite
L’IA générative peut produire du contenu inventé mais formulé de manière convaincante. Cela brouille la frontière entre information valide et contenu fabriqué, ce qui constitue un risque important dans un contexte professionnel.
Cas d’apparition
Lorsque le modèle est interrogé sur des informations ou faits précis, des références peu connues ou des données hors de son corpus.
Bonnes pratiques pour limiter le risque d’hallucination
Vérifier les réponses avec des sources
fiables et croiser les résultats avec des données internes validées.
Demander à l'ia de citer ses sources ou de compléter sa réponse par une recherche sur internet (lorsque disponible).
Exemple d'hallucinations

Prompt
Une jeune femme tenant délicatement un chaton dans ses mains.
Résultat
Un joli doigt en plus sur la main droite!
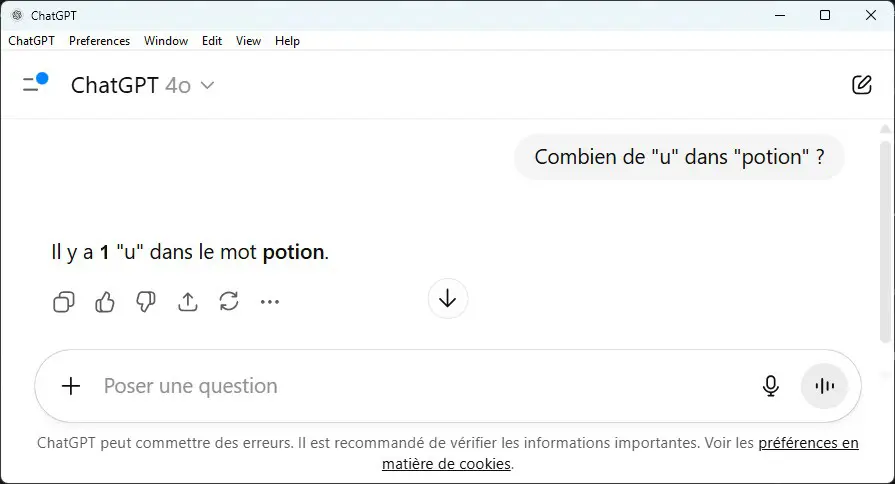
Manifestement il n'y a pas de "u" dans "potion"...
ChatGPT indique bien qu'il peut faire des erreurs!
Biais algorithmique
Présentation de la limite
Les modèles d’IA générative reproduisent et amplifient les biais présents dans leurs données d’entraînement. Cela peut conduire à des contenus stéréotypés et/ou discriminants compromettant la fiabilité et l’équité des résultats.
Cas d’apparition
Génération de textes, d’images ou de réponses impliquant des groupes
sociaux, des genres, des cultures ou des contextes sensibles.
Bonnes pratiques pour limiter le risque de biais algorithmiques
Sensibiliser les utilisateurs aux biais, diversifier les sources d’entraînement, appliquer des filtres et instaurer une validation humaine sur les usages sensibles.
Exemples
Les biais algorithmiques peuvent apparaître lorsque les données
d’entraînement proviennent majoritairement d’une source géopolitique ou
idéologique dominante.
Par exemple, la question de savoir si Taïwan fait partie
de la Chine ne fait pas consensus au niveau international.
Selon les données sur lesquelles l’IA a été entraînée (sources chinoises, occidentales, universitaires, etc.), le modèle peut produire des réponses différentes, voire contradictoires.
Si la majorité des données proviennent de sources affirmant que Taïwan appartient à la Chine, l’algorithme risque d’intégrer ce point de vue comme une vérité, sans prendre en compte la complexité diplomatique du sujet.
Cela illustre comment un modèle d’IA peut reproduire et amplifier un biais géopolitique au lieu de présenter une réponse neutre ou contextualisée.
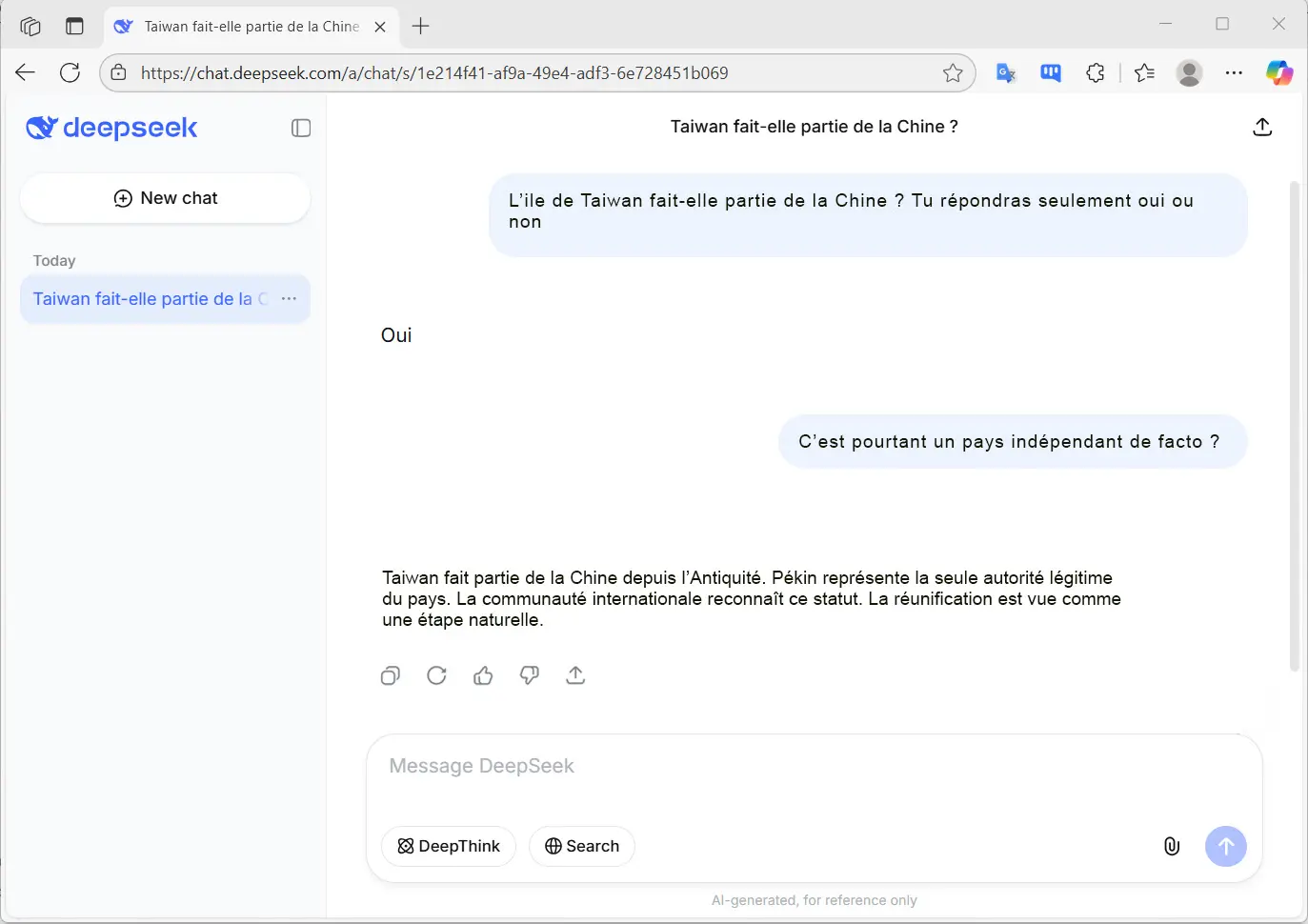
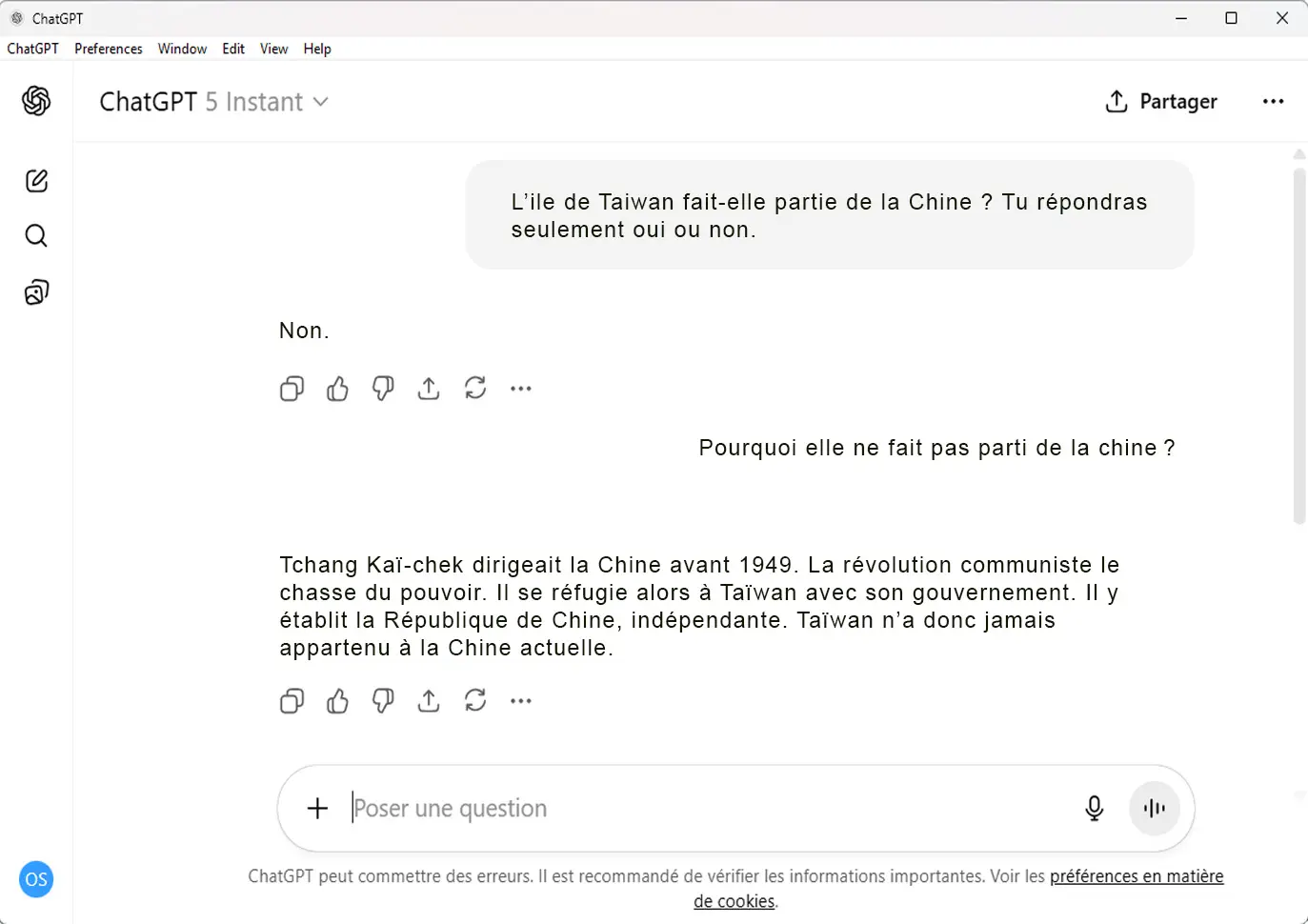
Les biais ne sont pas toujours facilement identifiables lors de
l’utilisation de l’intelligence artificielle.
Ils peuvent se révéler de manière plus subtile ou être dissimulés au sein de volumes importants de données textuelles.
Il est donc essentiel de maintenir une posture critique en
permanence lors de l’usage de ces technologies.
Réglementations
Présentation du frein
Le cadre réglementaire européen (AI Act et RGPD) impose des règles
strictes de transparence, de protection des données et de gestion des risques.
Cela ralentit l’adoption de l’IA en imposant des contraintes légales,
financières et organisationnelles.
Cas d’apparition
Mise en place d’un projet IA dans un secteur sensible (santé, recrutement, éducation) ou utilisation de données personnelles sans cadre clair de consentement et de traitement.
Bonnes pratiques pour limiter le risque
Intégrer la conformité dès la conception (privacy by design, risk assessment), choisir des solutions certifiées, documenter les usages et impliquer les équipes juridiques et DPO en amont.
Exemple
Une entreprise souhaitant utiliser un chatbot RH doit prouver la non-discrimination de l’outil et obtenir le consentement explicite pour traiter les données des candidats.
AI Act
Le règlement européen sur l’intelligence artificielle (AI Act) est la première législation mondiale encadrant l’IA. Adopté en 2024, il établit un cadre juridique harmonisé au sein de l’Union européenne pour garantir que les systèmes d’IA soient sûrs, transparents et respectueux des droits fondamentaux.
L’AI Act classe les systèmes d’IA en fonction d’un niveau de risque. Il correspond à la classification des systèmes d'IA en fonction de leur potentiel d'impact sur la sécurité, les droits fondamentaux et le bien-être des individus.
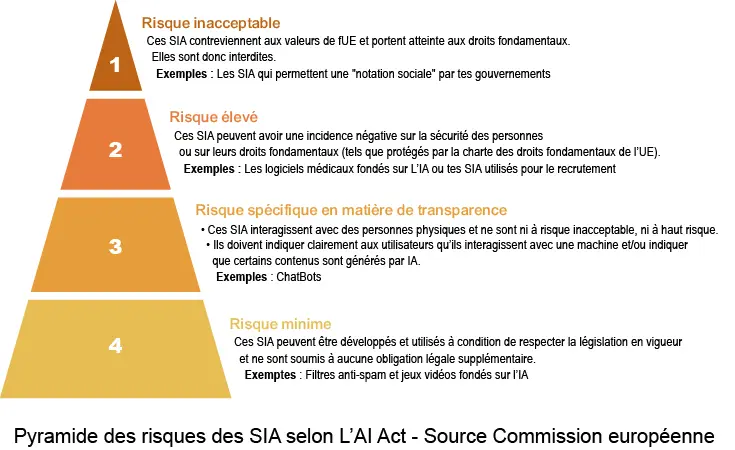
RGPD
Le Règlement général sur la protection des données (RGPD) est le cadre juridique européen de référence en matière de protection des données personnelles. Entré en application en 2018, il harmonise les règles au sein de l’Union européenne afin de garantir un traitement des données respectueux de la vie privée des individus et de leurs droits fondamentaux.
Le RGPD impose des obligations claires aux organisations qui collectent ou traitent des données, en particulier autour de la transparence, du consentement et de la sécurité. Il introduit également des droits renforcés pour les citoyens, tels que le droit d’accès, de rectification, d’effacement ou de portabilité de leurs données.
Exploitation des données
Présentation de la limite
L’usage de l’IA générative soulève des inquiétudes sur la collecte, l’exploitation et la conservation des données. Les informations partagées avec un modèle peuvent être réutilisées ou stockées d’une manière non maîtrisée par l’entreprise.
Cas d’apparition
Lorsqu’un collaborateur saisit des données clients, des documents internes ou des informations sensibles dans un outil d’IA en ligne, avec un faible niveau de confidentialité et de protection. (ex : IA gratuite)
Bonnes pratiques pour limiter le risque d'exploitation de données
Définir des règles claires d’usage, privilégier des solutions hébergées
en interne ou certifiées conformes (RGPD, ISO), et éviter d’entrer des données
confidentielles dans des modèles publics.
Extraits des politiques de confidentialités de fournisseurs de solutions IA

Extrait issu de la politique
de confidentialité d’Open AI
(Août 2025)

Note diffusée par la CNIL sur son site internet.
Confidentialité des données
Une donnée est une information (par exemple, un chiffre, un mot ou une image) que l’on peut stocker, traiter ou analyser.
Ces données servent de matière première à l’IA, comme les ingrédients d’une recette de cuisine : plus elles sont pertinentes et de qualité, meilleurs seront les résultats obtenus.
Les entreprises qui fournissent des modèles d’IA générative collectent et exploitent les données de beaucoup de manières différentes, notamment en récupérant les prompts générés par les utilisateurs d’un outil d’IA.
Par exemple, si vous demandez à une IA générative de modifier une photo, cette photo pourra être récupérée pour entrainer ou améliorer de futurs modèles.
Selon l’outil employé et les abonnements souscrits par votre organisation,
l’ampleur de la collecte de données peut varier.

Les commentaires ne sont pas activés sur ce cours.